
✅ 오늘의 학습 키워드
- 해시 테이블
- 해시 Set
- Substring
🔍 오늘의 문제 분석
- 문자열 s의 길이는 1 이상 100,000 이하이다
- 주어진 문자열에서 길이가 10이 되는 부분 문자열을 모두 확인한다
- 부분 문자열이 반복적으로 등장하는 횟수를 확인한다
- 등장 횟수가 2 이상이면 ArrayList로 반환한다
오늘의 문제는 문자열 s가 주어졌을 때, 이 문자열 안에서 10글자 길이를 가지는 부분 문자열 중 두 번 이상 나타난 문자열을 출력하는 문제이다. 처음에는 10개의 문자열을 key값으로 저장하고 key값의 등장 횟수를 value값으로 저장하는 HashMap을 떠올렸다. 하지만 등장 횟수가 두 번 이상만 돼도 조건에 충족하기 때문에 조회 후 연산하는 과정을 생략하기로 했다.
✨ 오늘의 회고
📌내가 적은 답안📌
더보기
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
HashSet<String> set = new HashSet<>();
HashSet<String> result = new HashSet<>();
for (int i = 0; i <= s.length() - 10; i++) {
String substring = s.substring(i, i + 10);
if (!set.add(substring)) {
result.add(substring);
}
}
return new ArrayList<>(result);
}
}
substring() 메서드를 사용해서 주어진 문자열에서 길이가 10이 되는 문자열을 추출했는데 이 문자열이 중복인지를 효과적으로 확인할 수 있도록 HashSet 자료구조를 사용했다.
만약 HashSet 인스턴스에 부분 문자열을 추가하려고 했을 때 false를 리턴하면 이미 같은 문자열이 존재한다는 뜻이므로 결과에 만족하는 문자열이 된다. 중복 없이 결과를 출력하기 위해서 두 번째 HashSet을 선언해서 저장하고 마지막에 ArrayList로 반환하도록 했다.
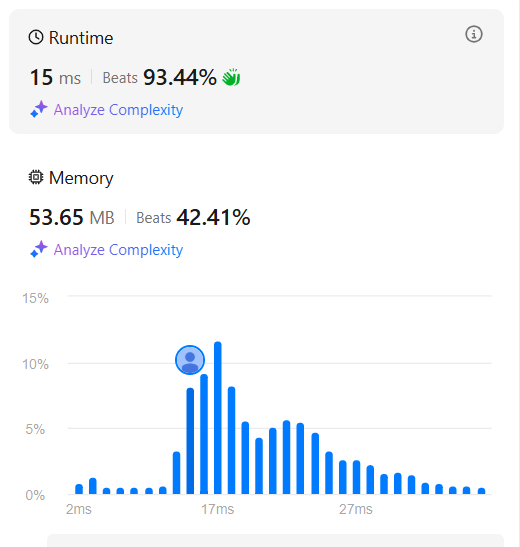
처음 위 코드로 실행했을 때 15ms 실행 시간과 53.65MB 메모리가 사용되었다. 코드를 개선하기 위해서 주어진 문자열 s의 길이가 10 이하라면 조건에 해당되지 않는 것을 이용해서 if 문을 반복문 전에 추가해 주었다. 아래 조건문을 추가한 것으로 불필요한 반복문을 실행하지 않아 실행 시간이 80%가 주는 결과를 얻을 수 있었다!👏
if (s.length() < 11 || s.length() > 10000) {
return new ArrayList<>();
}
'알고리즘 > [항해99] 1일 1알고리즘 스터디' 카테고리의 다른 글
| 99클럽 코테 스터디 13일차 TIL ✒️단어 정렬 (0) | 2025.04.17 |
|---|---|
| 99클럽 코테 스터디 12일차 TIL ✒️임스와 함께하는 미니게임 (0) | 2025.04.16 |
| 99클럽 코테 스터디 10일차 TIL ✒️ 평행선 (0) | 2025.04.11 |
| 99클럽 코테 스터디 9일차 TIL ✒️체이닝 방식으로 HashMap 구현하기 (0) | 2025.04.10 |
| 99클럽 코테 스터디 8일차 TIL ✒️문자 개수 세기 (0) | 2025.04.10 |